Abstract
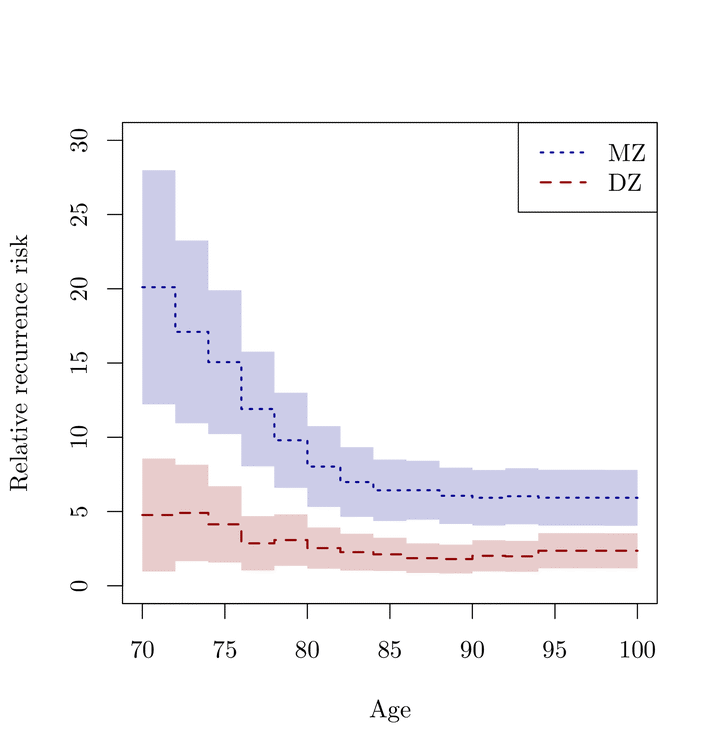
Family studies provide an important tool for understanding etiology of diseases, with the key aim of discovering evidence of family aggregation and to determine if such aggregation can be attributed to genetic components. Heritability and concordance estimates are routinely calculated in twin studies of diseases, as a way of quantifying such genetic contribution. The endpoint in these studies are typically defined as occurrence of a disease versus death without the disease. However, a large fraction of the subjects may still be alive at the time of follow-up without having experienced the disease thus still being at risk. Ignoring this right-censoring can lead to severely biased estimates. The classical liability threshold model can be extended with inverse probability of censoring weighting of complete observations. This leads to a flexible way of modelling twin concordance and obtaining consistent estimates of heritability. The method is demonstrated in simulations and applied to data from the population based Danish twin cohort to describe the dependence in prostate cancer occurrence in twins.